Всем привет!
Окей, этот выпуск будет немного неформатный, по той причине что у меня появились первые данные 🙂 В прошлый раз, мы говорили о языке julia и о том, как писать простые программы с его использованием. Сегодня — поговорим о реальных результатах и уже в следующий раз, продолжим с julia. Что я имею ввиду, когда говорю о данных? «Данные» — это различные характеристики (возраст популяции, размер кода организмов, количество мутаций, количество циклов в коде и т.д.) тестируемой популяции, которые изменяются со временем. Таким образом, их можно визуализировать в виде графиков.
Если в двух словах говорить о том, как были получены эти данные и связанные с ними графики, то дело происходило так: сначала создавалась «пустая» (без кода) популяция из 250 особей. У каждого организма такой популяции было 7000 юнитов энергии. Далее они размножались и мутировали, а отбор делал свое грязное дело (убивал организмы (10 штук), количество энергии которых было минимальным). Каждые 5 секунд система делала срез данных куда входили следующие поля:
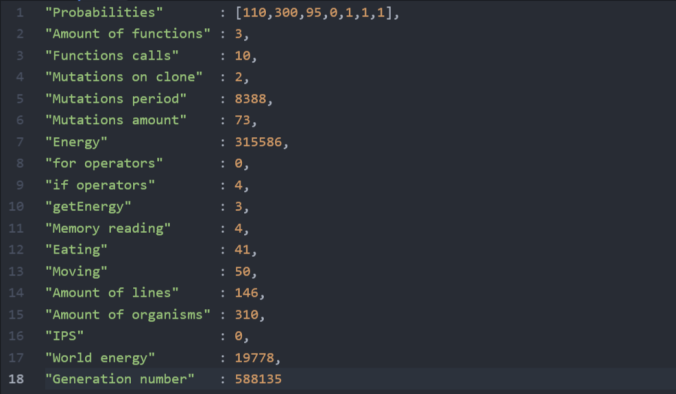
Давайте, я поясню детальней что означают эти поля. Сверху-вниз:
- Вероятностные коэффициенты. Определяют, как часто в коде появятся мутации добавления, изменения и удаления кода (первые 3 числа). Последние 3 числа определяют: количество мутаций при клонировании, период дополнительных мутаций и количество доп. мутаций после этого периода. Все эти параметры так же могут мутировать у каждого организма по отдельности
- Количество функций в коде организма
- Количество вызовов этих функций
- Фактическое количество мутаций применяемое после клонирования
- Период, после которого применяются дополнительные мутации
- Количество дополнительных мутаций применяющихся после периода доп. мутаций
- Количество энергии организма
- Количество операторов for в коде организма
- Количество операторов if в коде организма
- Количество вызовов функции getEnergy() (аналог примитивного зрения)
- Количество обращений к внутренней памяти организма
- Количество вызовов функции eatXXX() (еда)
- Количество вызовов функции stepXXX() (движение)
- Количество строк кода организма
- Количество организмов в текущей популяции
- Текущий IPS (Iterations Per Second)
- Количество энергии в «мире» доступной для поедания
- Возраст популяции
Каждый из этих параметров меняется со временем и таким образом формируется большой JSON файл со всеми срезами, и на его основе рисуются графики. Вот такие:
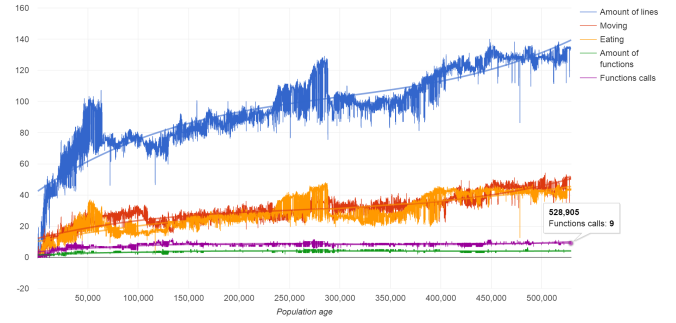
Начнем с того, что по горизонтали у нас «возраст популяции». Что это значит? Это значит, что в самом левом углу (где ноль) популяция начала существование, а в самом правом (где значение 500000) — она находится сейчас. Сами числа определяют количество умерших организмов с момента рождения популяции и до выбранного момента. В некотором смысле — этот параметр означает «текущее поколение» и он напрямую связан со временем. Чем больше число, тем дольше существует популяция…
Видите этот синий график сверху? Это количество строк кода у самых лучших организмов популяции. Вообще, все эти графики строятся на основе «лучших из лучших» организмов. Такой себе показ «альфа самцов» 🙂 (в этом месте должны проснуться феминистки). Для нас важно то, что всреднем, синий график растет. Это означает, что организмы увеличивают размер своего кода, при этом затраты энергии тоже увеличиваются. Важно помнить, что увеличение количества строк кода — задача вполне тривиальная. А вот увеличение кол-ва строк одновременно с увеличивающейся потерей энергии — нет. Все это означает, что удлинение кода происходит с одновременным увеличением его эффективности. В нашем случае — это способность «находить» больше энергии для пропитания, чем твои предки. Таким образом отбор работает в сторону тех организмов, которые мутируют в направлении более эффективного кода. Затраты увеличиваются, потому что каждая дополнительная строка кода приравнивается к одному юниту энергии. То есть, чем больше код организма, тем больше энергии он тратит с течением времени. Даже в том случае, если он ничего не делеат (просто итост на месте) — энергия все равно тратится. Это обстоятельство — один из факторов, который заставляет систему стремиться к увеличению потребления энергии. Давайте взглянем на код одного из лучших организмов (приблизительное поколение: 500000):
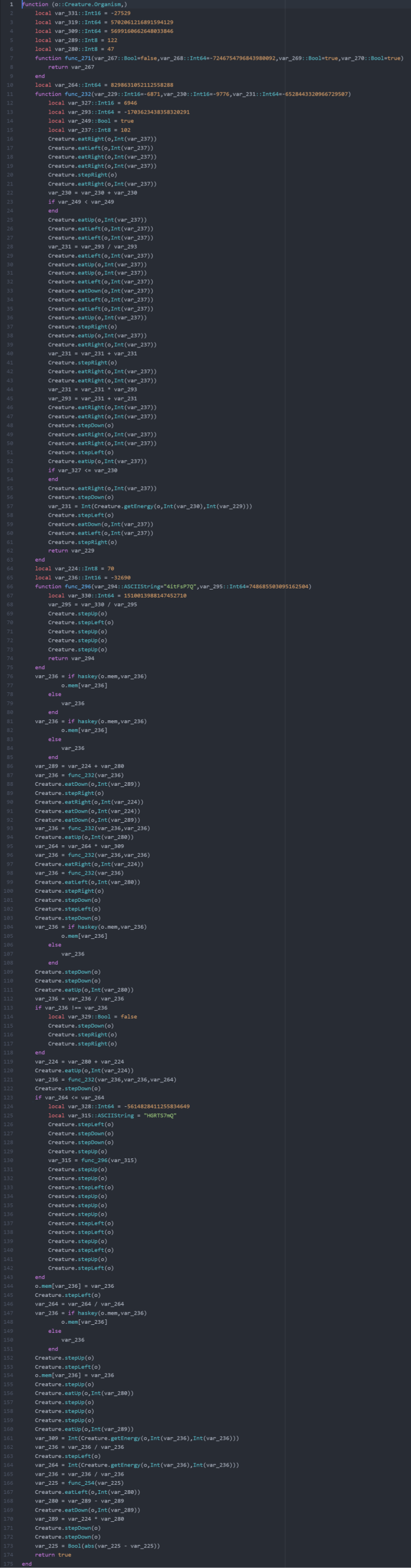
Что мы здесь видим? Во-первых, сверху (строки 2-66) распологаются объявления функций и переменных. Далее, можно заметить вызов функции func_232() целых 5 раз. Видимо для жизни организма она играет центральную роль (у всех его «родственников» она тоже присутсвует). Заглянув внутрь нее, мы видим, что это по-сути микс движения и пожирания всего, что вокруг. Менее важной является функция func_296(). Она вызывается только раз (строка 130) и служит для дополнительного передвижения организма. Далее — интересней. Обратите внимание на строку 166. Там происходит вызов функции func_254(), но сама функция не определена в коде. Что это означает? Это означает, что текущий лучший организм содержит логическую ошибку (одна из предыдущих мутаций удалила эту функцию), которая ведет к исключению в строке 166. То есть, далее, код не выполнится. Строки 167-174, никогда не будут выполнены. По сути — это баласт, за который забирается дополнительная энергия. Разумеется, со временем отбор конечно же вычистит его, но на момент сбора данных это не мешало нашему подопытному кролику быть лучшим в популяции себеподобных. В остальном, там нет ничего интересного. Весть код — это смесь отностельно оптимального движения и поедания всего, что находится вокруг организма.
Идем дальше. Желтый и красный графики — определяют количество вызовов функций «двигайся» и «ешь». Впринципе, эти показатели должны расти прапорционально с ростом размера кода (хотя здесь есть нюансы — рост может замедлиться при оптимизации кода). Как видно по этим графикам «есть», по сути, означает — «двигаться». Как минимум на этом этапе жизни популяции. И это логично, ведь движение напрямую влияет на то, сколько энергетических блоков будет найдено.
Окей, что еще? Чуть ниже, можно увидеть зеленый график — это количество функций. О них мы уже говорили выше. Это обычные функции (оператор function), которые программисты используют для абстрагирования. Я не учил организмы, как их использовать. Они сами «поняли», что функции — это более оптимальный выбор нежели просто линейный код. Давайте я объясню. Обратите внимание на фиолетовый график — он тоже растет. Хоть и не так быстро, но все же растет. Оба, они показывают, как часто организм использует функции для изменения своего поведения. Количество вызовов функции всегда больше количества самих функций. Это логично. Ведь, если Вам нужно сделать 50 шагов. Вы можете вызвать 50 раз функцию stepXXX() или написать функцию с 10 вызовами stepXXX() внутри и вызвать её 5 раз. Такой код будет занимать 15 строк. Видите разницу? 50 против 15. Второй вариант короче, а значит, тратит меньше энергии. А, значит, более экономный и выживет с большей вероятностью. Именно так и просходит — оптимальные программы имеют больший шанс на выживание, а значит и на то, что именно их потомство «продолжит их дело».
Еще один график, который я бы хотел обсудить — это потребление энергии. Он означает: сколько лучшие организмы потребляют энергии за свою жизнь. Если этот показатель растет — это означает, что они умудряются находить энергетические точки все лучше и лучше. Давайте взглянем на него:
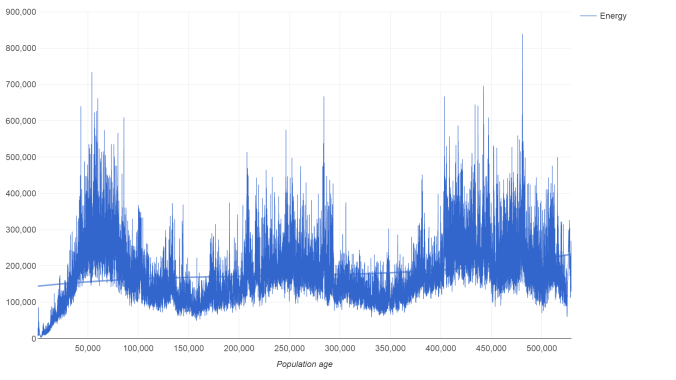
Обратите внимание — первые 50000 особей активно увеличивали потребление энергии. После наступил медленный рост с перепадами, вплоть до самого конца (до 500000 поколения). Среднее увеличение показывает отдельная линия в центре графика (полином, построенный по данным энергии). Она передает сглаженное совокупное трендовое значение всего графика. Именно на её основе, мы делаем вывод о росте этого параметра.
Чтобы не мучать Вас дальше, я опущу остальные параметры. Последнее, на что бы хотел обратить ваше внимение это видео! Видео того, как в одной из популяций появилось примитивная групповая охота на случайно разбросанную энергию. Смотрим здесь.
Давайте подведем итог:
- рассматриваемое поколение (приблизительно 500000) «научилось» писать относительно оптимальный код используя функции
- общий график потребления энергии растет
- общий график размера кода тоже растет
- количество таких операторов как: for, if, getEnergy,… растет медленно
- основная логика организмов (как минимум на текущий момент) — это «есть» и «двигаться». Именно на эти параметры направлен отбор
- эволюция сложного поведения процесс очень медленный и неверояно затратный (относительно CPU time). Результаты полученные в этой статье собирались 6 дней постоянной работы при 12% загрузки CPU
Всем спасибо, я спать 🙂